
 We often get asked the question “When is it best to OCR our documents when using Aquaforest Searchlight, before or after we have uploaded them into SharePoint?”
We often get asked the question “When is it best to OCR our documents when using Aquaforest Searchlight, before or after we have uploaded them into SharePoint?”
The answer to this question becomes transparent once you know how the OCR process works within the product.
Here is a little bit about the product……
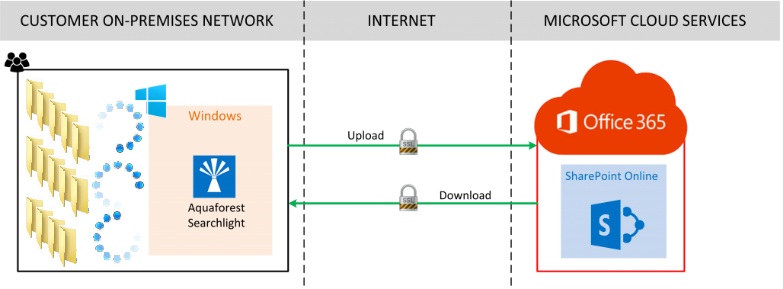
Aquaforest Searchlight is a client software which can be installed and run on both Windows client or Windows server operating systems. The software is recommended to be installed on a dedicated machine and should NOT be installed on the SharePoint server.
The product is designed to automatically take non-searchable documents such as Image PDFs, Scanned Image Files and Faxes (TIFF, BMP, JPG, PNG) and convert them into fully Searchable PDF format.
There are 2 main stages which take place when running a Searchlight library: the Audit stage and the OCR stage.
Before explaining these 2 stages, let’s first clarify what is a Searchlight library. A Searchlight library is an object in Aquaforest Searchlight that can consist of either:
- one or more SharePoint site collections, SharePoint sites, SharePoint document libraries and/or SharePoint lists.
OR
- one or more File System paths
All Searchlight libraries are displayed in the Dashboard as shown below:
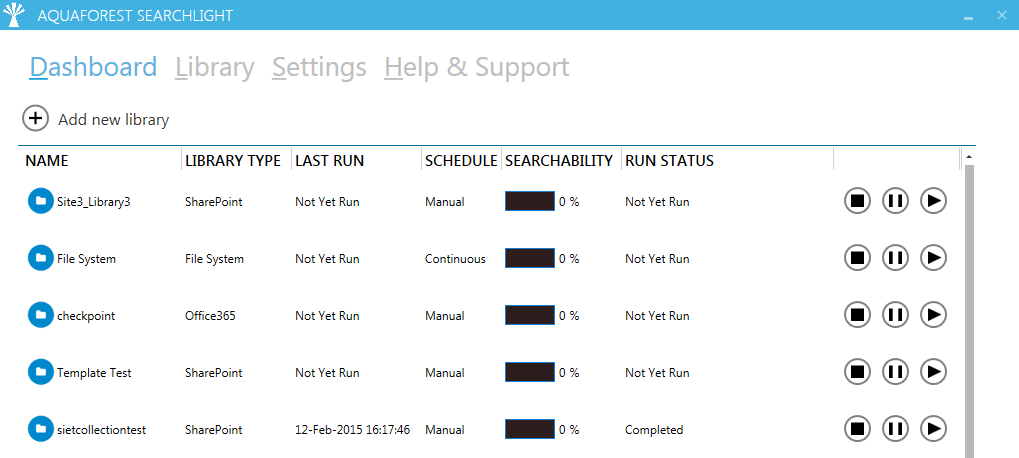 Figure 1: Searchlight libraries
Figure 1: Searchlight libraries1. AUDIT AND OCR STAGES
The Audit stage analyses each SharePoint site collection, site or document library/list in a Searchlight library and checks the searchability status (searchable, partially searchable and image-only) of each document in the library. See the following blog for more explanation regarding different searchability statuses.
The very first time a Searchlight library is run, Aquaforest Searchlight downloads each and every PDF document (and TIFF, BMP, JPG, PNG, if specified in the Document Selection rules) to a temp folder on the Searchlight host machine and checks their searchability status. The searchability status along with other information like modified date, created date, etc. of each document are stored in a SQLite database.
After analysing all documents, Searchlight proceeds to select the documents whose searchability status match the Document Selection rules for the OCR stage.
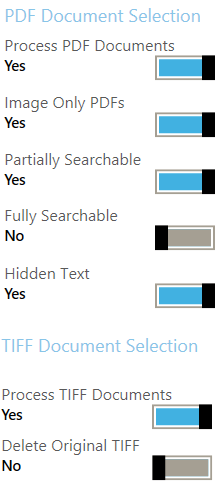
Figure 2: Document Selection rules
The selected documents are OCR’ed and those that were successfully OCR’ed are uploaded back to SharePoint. The new searchability status of each document is then updated in the SQLite database.
Finally, all the downloaded and OCR’ed documents are deleted from the Searchlight host machine.
If new documents are added to a SharePoint document library that is contained in the Searchlight library and ran again, Aquaforest Searchlight will only download and process the new documents.
Now that you know how the process works it can make sense for customer migrating to SharePoint to OCR their documents before they are uploaded into SharePoint.
