
This blog has been created to assist users in trouble shooting issues they may experience when using the Aquaforest OCR SDK for .Net software.
Replicating Issues Using Sample Applications
The Aquaforest OCR SDK comes with a number of sample applications written in both VB and C#. The sample applications illustrate the simplicity in which the OCR SDK can be used to convert Tiff to PDF or OCR image files. These sample applications can also be used to test any issues you may experience in your own project; by using one of the applications you can narrow down the root cause of the problem you’re experiencing as well reducing the turnaround time for resolution. If you do come across an issue we recommend that you follow the steps below:- Use the same file set on one of our sample applications.
- If you can reproduce the issue with a sample application, send a copy of the test file and information on which sample application you used to support@aquaforest.com
Generating Additional Debug Information
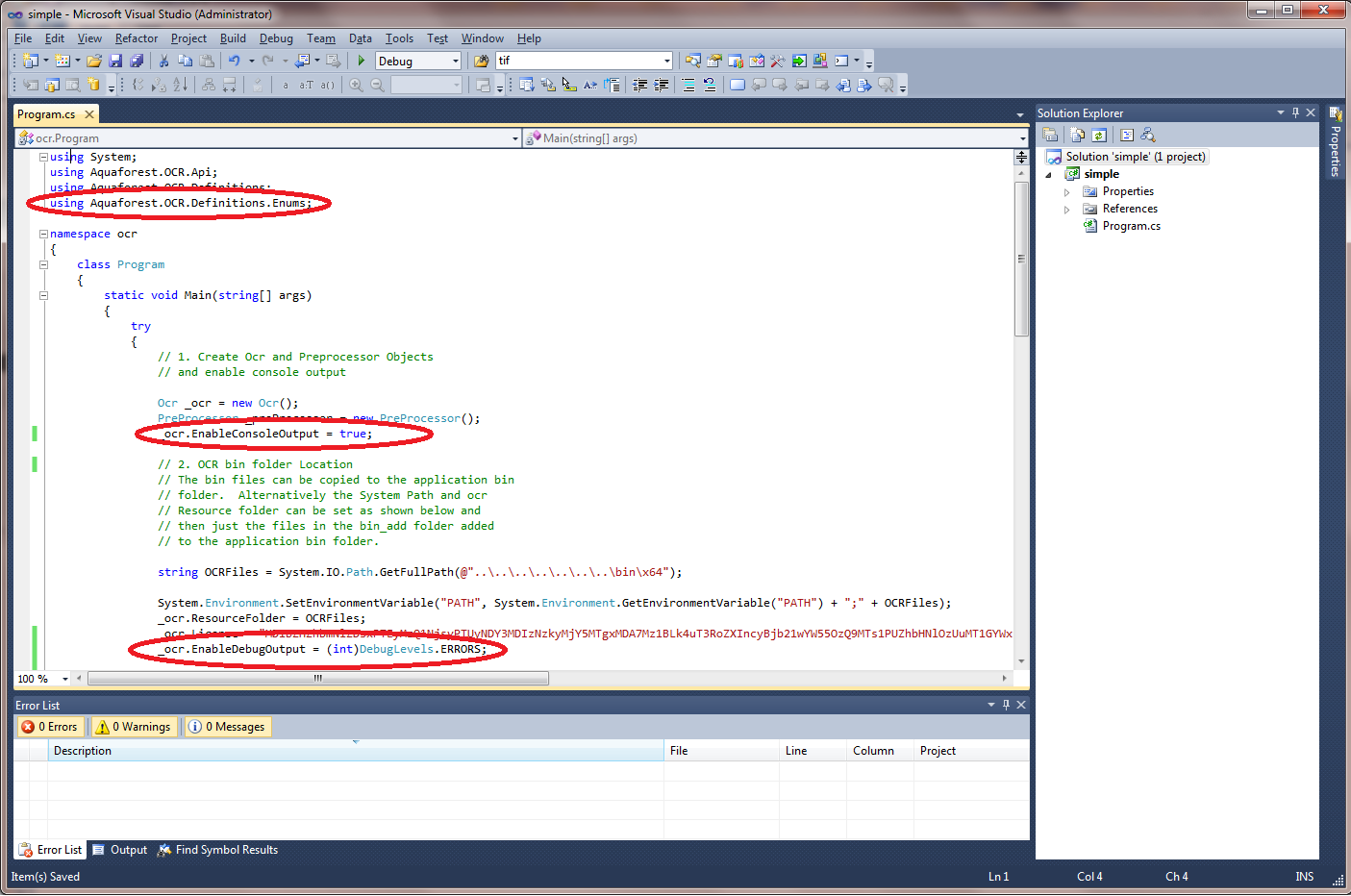
- If you are unable to reproduce the issue with a sample application, then include the lines of code circled in red from the screenshot below into your own code to generate further debugging.
- Run your application once more and send the output generated by the debug.
Analysing Temporary Files
This can be very useful if you wish to see what effects the pre-processing settings have had on a page before it is passed to the OCR engine.- Ensure you have made a reference the following in your namespace: using Aquaforest.OCR.Definitions.Enums;
- Add the following code to your project: _ocr.EnableDebugOutput = (int) DebugLevels.LEAVE_TEMP_FILES_IN_PLACE;
- C:\Users\username\AppData\Local\Temp\AquaforestOcr
- Also accessible by %temp%\AquaforestOcr
- extract (folder)
- source_tiff (folder)
- 0_1.bmp
- 0_1.hocr
- 0_1.tif
- output.pdf
- output.txt
