PDF is one of the most common file types held within a SharePoint document store and yet depending upon the version of SharePoint the “out of the box behaviour” may not be quite what users expect. Consequently PDF users felt that PDF files were very much “second class citizens” in versions of SharePoint prior to 2013.
PDF and SharePoint
In SharePoint versions prior to 2013 there was no PDF Icon and PDF documents would not be indexed for SharePoint search unless a separate iFilter was installed.

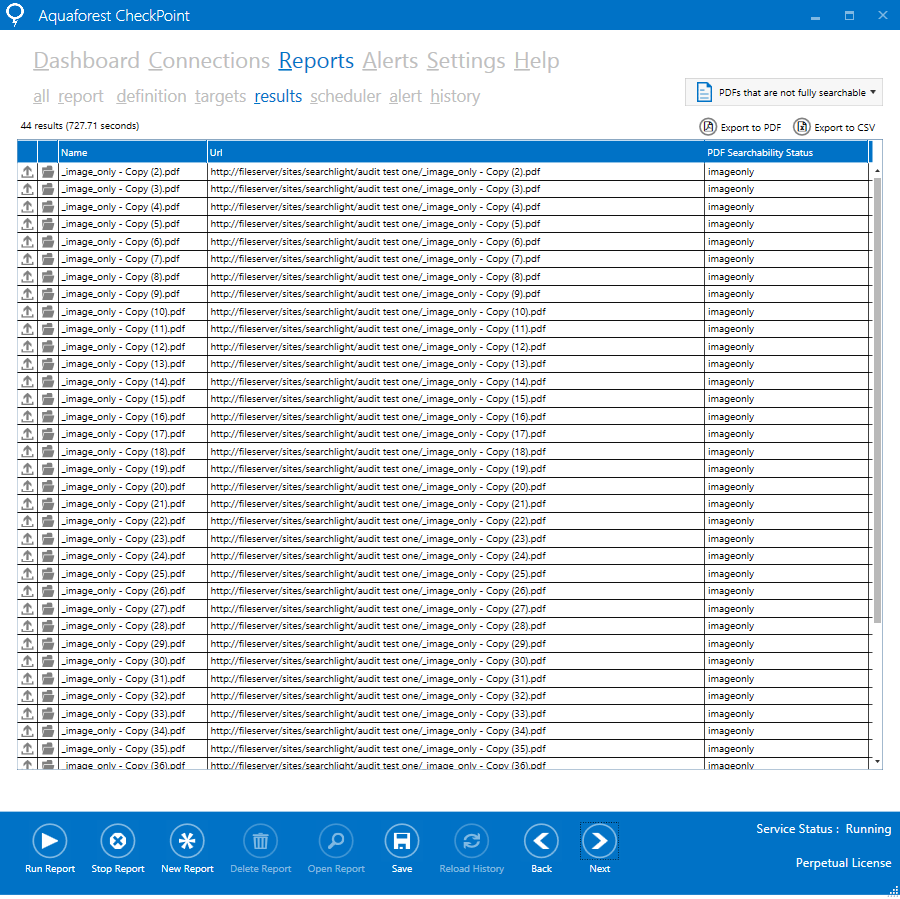
Aquaforest Searchlight can be used to fix Image PDF Indexing. See the Image PDFs section below for more details.
The PDF icon and indexing issue in SharePoint 2007/2010 could easily be addressed by following the instructions here whereas allowing PDF files to open in the browser can be fixed by following the instructions in this blog.
The good news is that PDF is finally recognized as a file type from SharePoint 2013 onwards and Microsoft added their own PDF Format Handler so that PDFs can be automatically indexed without requiring a third party iFilter. Another piece of good news is that it is now straighforward to enable PDF document previews in search results.
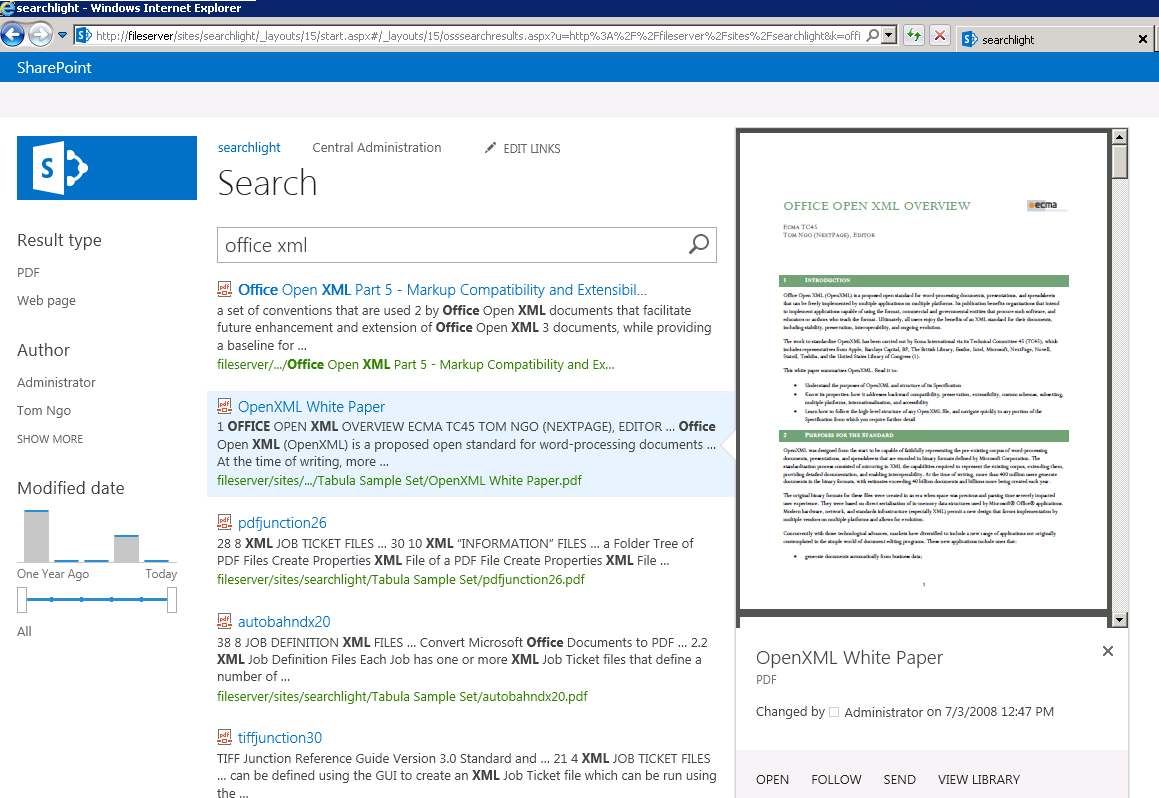
In addition, the situation regarding viewing PDF files from within Microsoft SharePoint has some issues as is well explained in this article.
However, one downside of SharePoint 2013 is that third party iFilters are no longer supported for use via SharePoint Search and this means that a number of aspects of PDF content can no longer be searched on as shown below:
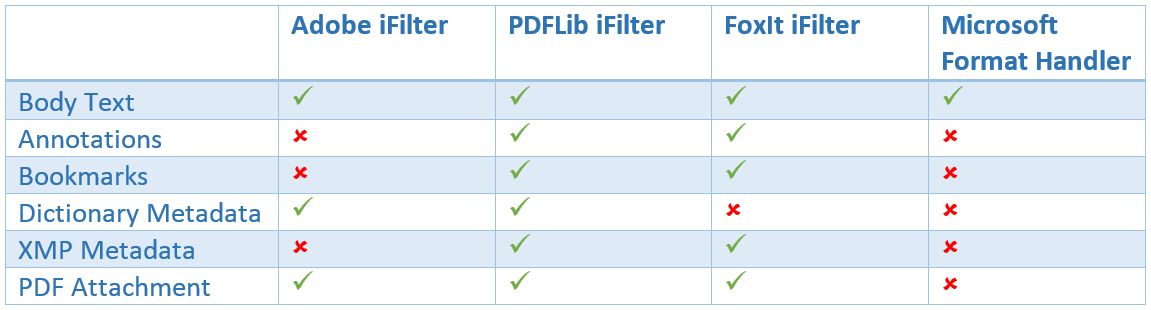
Since the release of Service Pack 1 in July 2014 it is now possible to install and configure third party iFilters in SharePoint 2013.
Image PDFs
One common issue is that many PDF files are either totally or partially image files having originated from scanned documents or faxes.
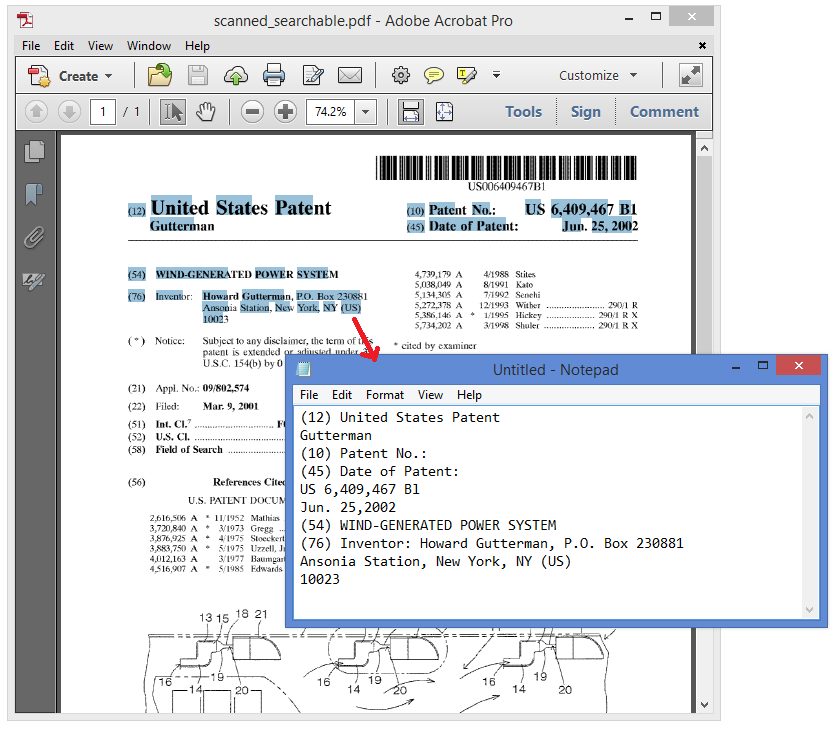
A searchable PDF has text that can be selected and searched.
 |
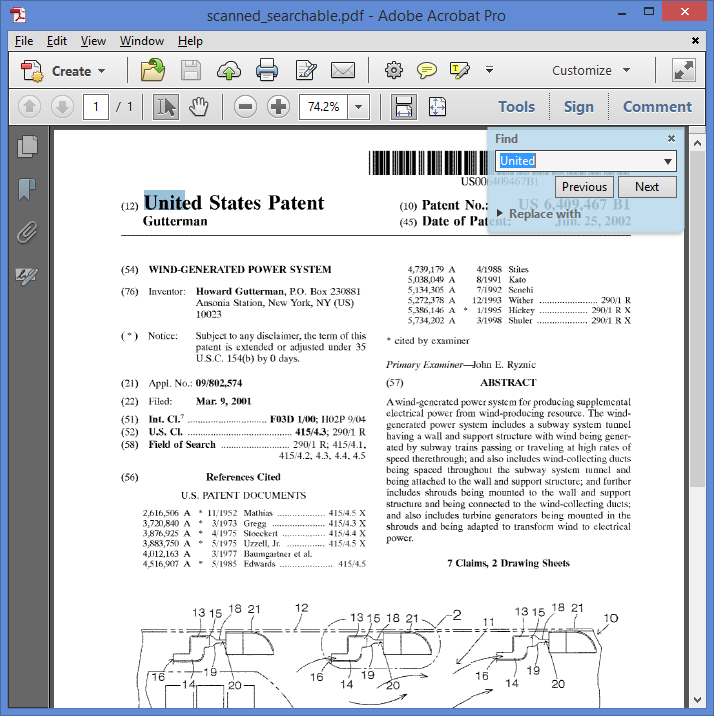 |
Conversely an image PDF consist of images only. If you try to select text on a page, you won’t be able to. Instead the whole image in the page is selected.
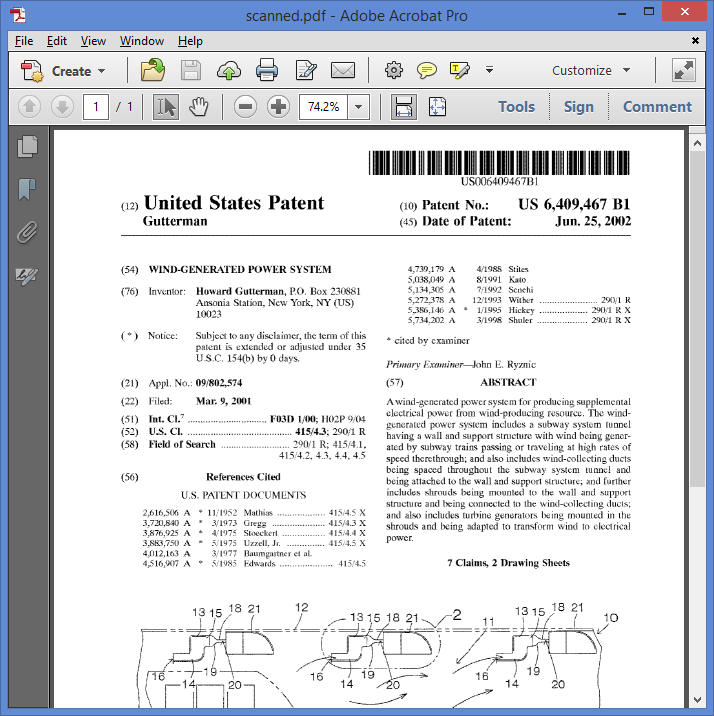 |
 |
Likewise, if you try to search a particuar text on the document, it won’t return any results.
These documents are considered “dead content” because their contents are essentially images and, as a result, cannot be searched or indexed.
Many organizations have tens of thousands (if not hundreds of thousands) of these documents in their SharePoint libraries. They add no value as they are invisible to the SharePoint search engine because the SharePoint crawler cannot index them. Without manually opening theses PDFs one by one and reading them, it is virtually impossible to find which documents contain which particular information. Consequently, these documents are costing storage space without adding any value to the organizations.
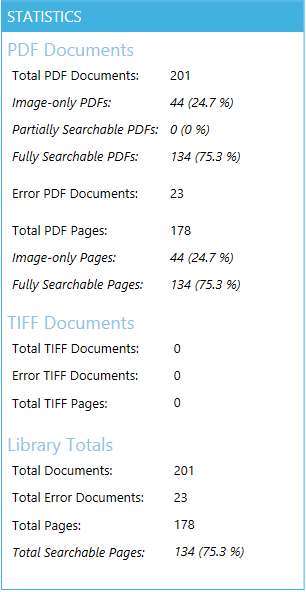
To make these documents discoverable again, they need to be transformed into a format that can be searched and indexed by the SharePoint crawler. This is where Aquaforest Searchlight comes in. Aquaforest Searchlight is able to audit SharePoint document stores, identify image-only PDFs and turn them into searchable PDFs using Optical Character Recognition (OCR), thus allowing the SharePoint crawler to index them.
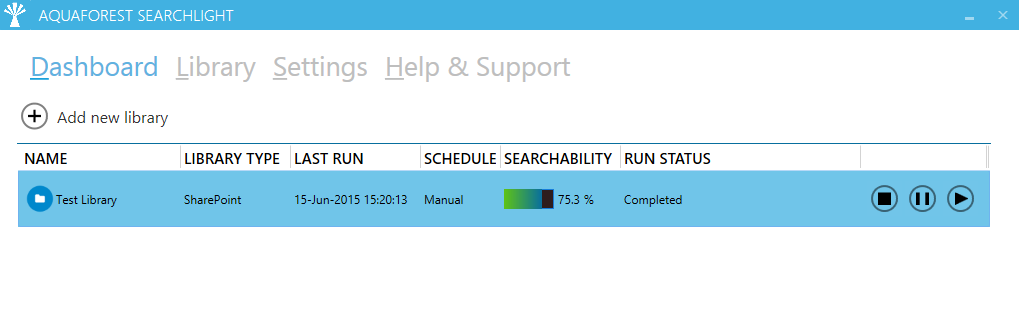
In addition to identifying Image-only PDFs, Aquaforest Searchlight can also identify Partially Searchable, Fully Searchable, TIFFs and Error (due to file corruption) documents.
To see how Aquaforest Searchlight works, check this video demo.
Another tool that can identify image-only PDF documents is Aquaforest CheckPoint. However, this tool does not provide OCR capabilities.